



.svg)



There's a persistent belief in voice AI that more data solves everything. But when you work with contact centers handling millions of calls, you learn quickly that this isn’t quite true.
At Replicant, where our AI agents handles millions of customer conversations, we’ve seen both sides of that equation:
👉 The right data can dramatically improve automation and customer experience
👉 The wrong data can quietly degrade performance and trust
The difference comes down to how you balance your data, not how much you have.
What actually moves the needle
Contact center audio is messy. Customers call from cars, use speakerphone, talk over agents, and speak in domain-specific terminology that means nothing outside your specific industry. A model trained on clean, generic speech will fall apart the moment it hits a real queue.
What works is specificity: training on the language patterns, workflows, and edge cases that show up in your calls. Policy numbers, product names, the way an angry customer phrases a billing dispute. That context is what separates a model that demos well from one that actually resolves calls.
The 5% of interactions that are hardest to handle—hesitations, corrections, emotionally charged speech—also tend to drive the most escalations. Those aren't edge cases to deprioritize. They're where your model needs to be sharpest.
Where things go wrong
Bad labels are probably the most underestimated problem in automatic speech recognition (ASR) development. If your transcripts are inaccurate, your model learns those inaccuracies at scale. By the time you notice degraded performance, the damage is already baked in.
Volume without relevance is just as dangerous. Pulling in large datasets that aren't closely tied to your use case can actually pull the model away from what matters, which in a contact center means worse performance on the calls your automation is built around.
Representation skew creates brittle systems. If one call type, one accent, or one workflow dominates your training data, performance looks great until it doesn't. And when it breaks, it tends to break hard.
How we think about it at Replicant
The framework we keep coming back to is balance across three tensions:
- Breadth vs. relevance. You need diversity in your data, but it has to reflect your actual production traffic, not just what was easy to collect.
- Quantity vs. quality. A smaller, cleaner dataset consistently outperforms a larger, noisier one. The question we ask: would we trust this transcript if it showed up in a live customer call?
- Stability vs. adaptability. Models need to improve over time, but not in ways that introduce inconsistency. Constant retraining without discipline is its own form of drift.
In practice, this means curating aggressively before anything goes into training. Raw conversation data isn't ready to use. Filtering, deduplication, and transcript validation aren't optional steps.
It also means weighting data by what actually matters for automation: high-confidence transcripts, core workflows, recent production traffic. And it means treating your own system's failures as a training resource. Misrecognitions, escalations, failed automations—that's some of the most valuable data you have.
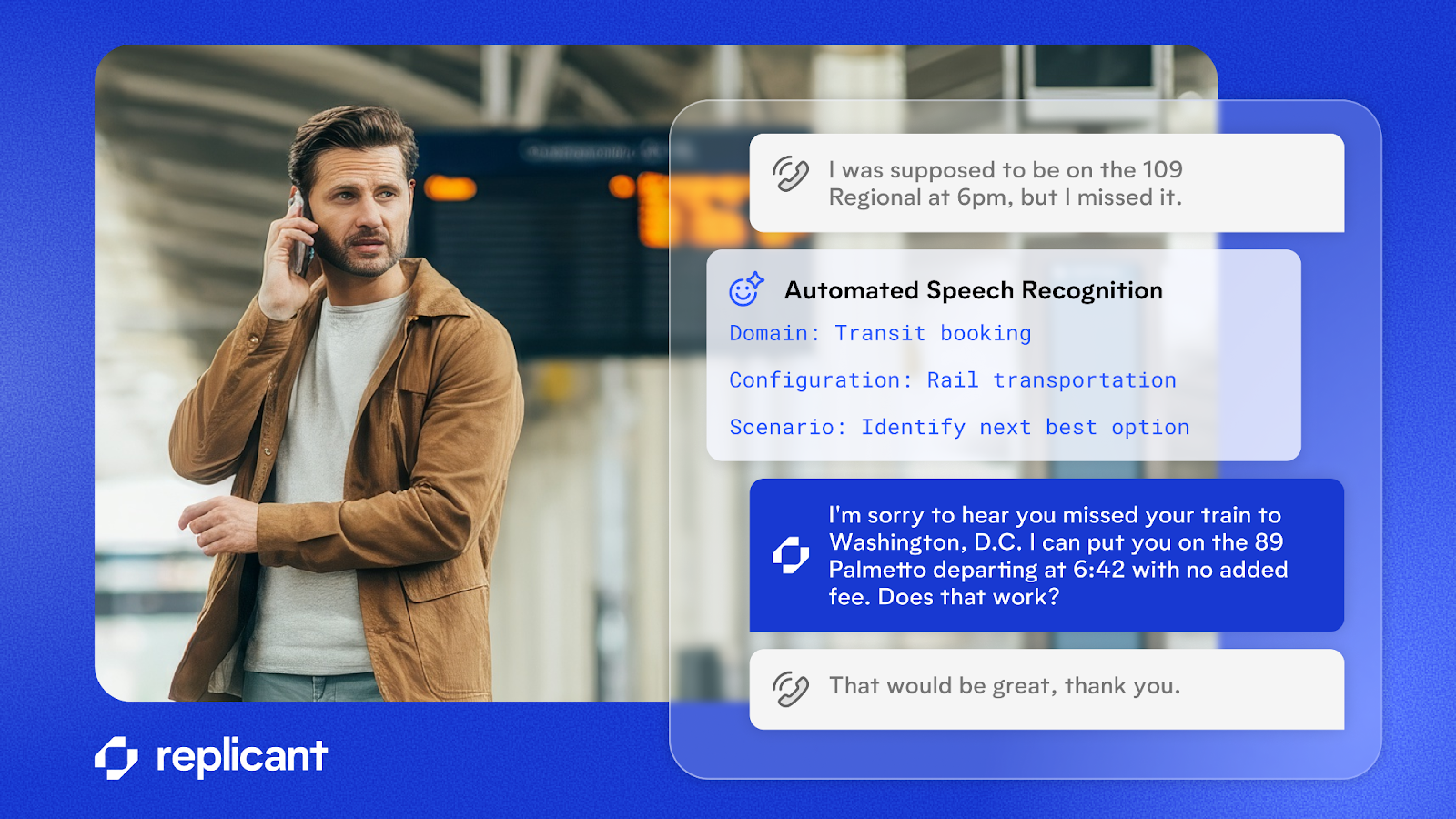
For product leaders, data isn’t just an input, it’s a strategic asset
From Replicant’s experience:
- Purpose-built, production-aligned data (and the process to validate it) is the single biggest lever to improve practical ASR performance and downstream automation. We optimize how they’re applied in production through domain-specific configuration, evaluation, and continuous feedback loops. The result is improved effective WER (word error rate) and higher automation/containment in real contact center workflows.
- QA and human-in-the-loop pipelines matter. Fixed transcripts and intent correction feed the model the right signal. Without that loop, noisy labels and skewed datasets will quietly erode performance.
- Evaluation must tie to outcomes. Track task completion and containment first; use WER and other technical metrics to explain why those business metrics moved. Our evaluation artifacts emphasize business-aligned, scenario-level pass/fail metrics for this reason.
Striking the right balance for high-quality voice AI
Final thought: The goal isn’t to feed your model more data. It’s to feed it the right data, in the right balance, at the right time, with the tooling and feedback loops to keep that balance as production evolves. That’s what turns an ASR model into a production-ready voice AI system.
Schedule time with an expert to learn more about how Replicant can transform your contact center with AI.
