



.svg)



The single most important principle in evaluating AI agents is deceptively simple!
Carefully match your evaluation to the behavior you actually want. Once that alignment is correct, then the goal is to improve the metric.
While it sounds simple, failures in evaluation design – not modeling power – are increasingly becoming the primary driver of low-performing AI.
Teams often construct an evaluation that is easy to compute, such as defaulting to an academic benchmark. It’s no coincidence why. Many of these benchmarks are open-sourced and widely circulated. They feel clean, standard, and they can be used as a bar to measure against prior art.
But precisely because they are designed to be use case-agnostic, they rarely measure what is meaningful.
Invariably, such evaluations are only loosely correlated with the behavior that actually matters in production. And this means that improvement in evaluation scores does not translate to improvement in customer experience, business outcomes, or system reliability.
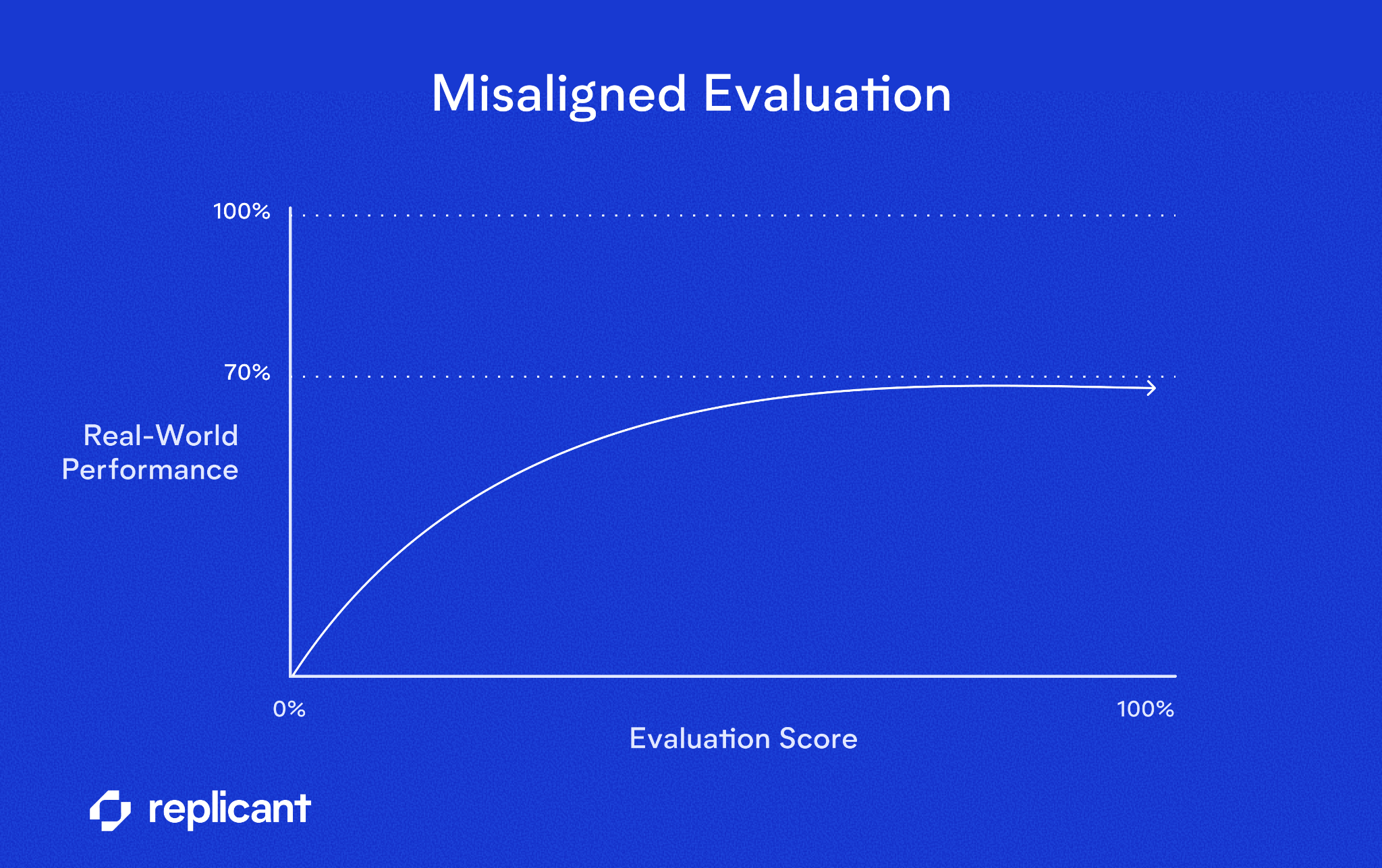
Misalignment in the relationship between evaluation and optimal behavior is effectively noise. And noise sets an upper bound on how good your system can actually become.
Imagine your evaluation metric correlates only 70% with true production success. Even a theoretically perfect system under that metric cannot exceed that 70% alignment with real-world objectives. Past a certain point, additional tuning produces diminishing returns and fragile gains that collapse under distribution shift.
On the other hand, a great evaluation improves over time, alongside the system, always aligned with real-world outcomes. When the metric goes up, production performance reliably improves, too.
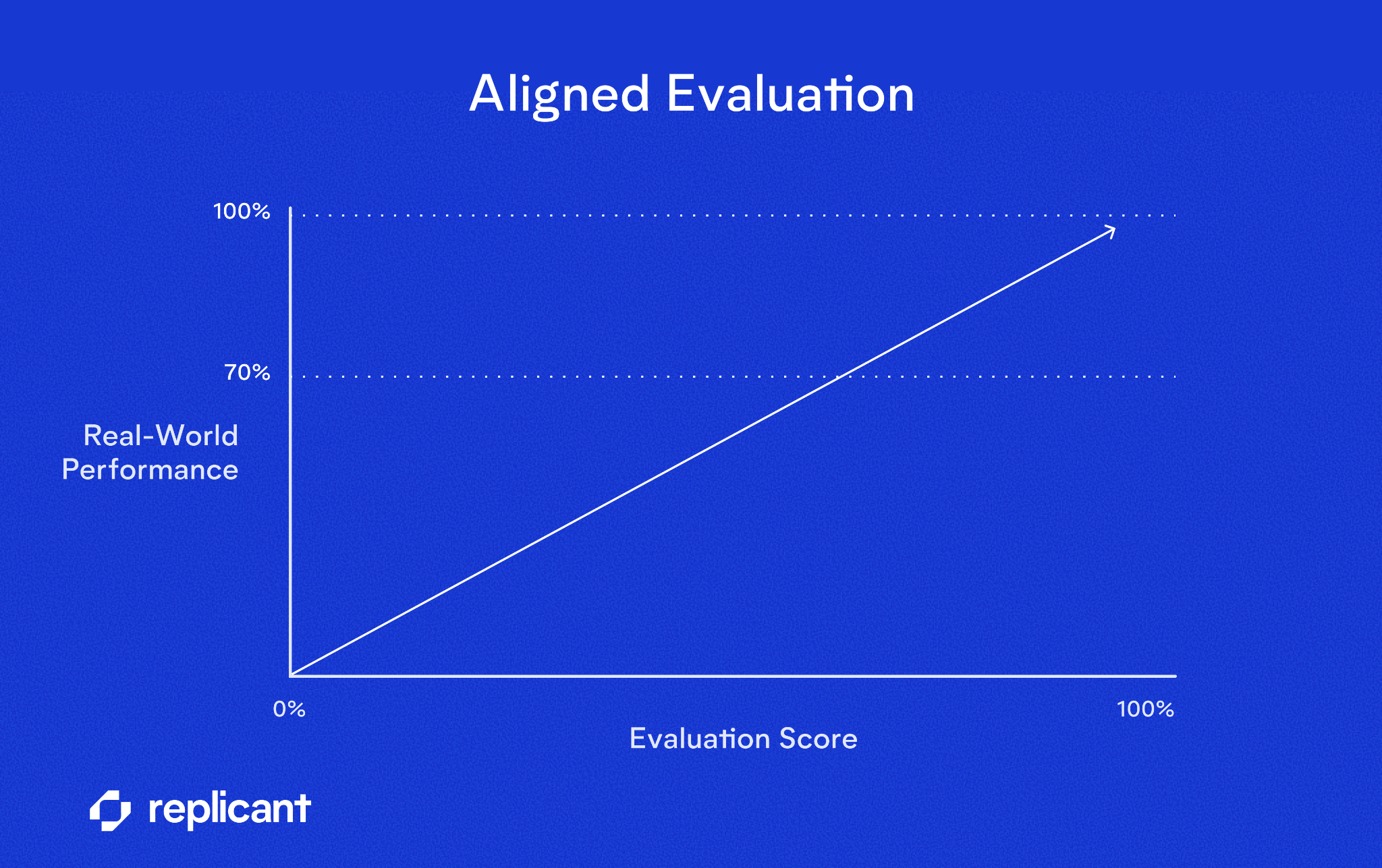
That alignment creates a clear runway for sustained progress instead of an artificial ceiling. A good evaluation has one defining property: If the score goes up, the real-world behavior gets better.
Ingredients of a great evaluation
A strong evaluation rests on three pillars:
- Metrics. Choose metrics that reflect the real objective, including the right tradeoffs (precision vs. recall, weighting of critical cases, task success vs. surface accuracy). If the metric improves, real behavior should improve.
- Data. Use production-aligned data that reflects true distributions, noise, and edge cases. Synthetic data is scaffolding; real data is ground truth.
- Statistical rigor. Ensure sufficient sample size and statistical stability. Guard against regression to the mean, distribution shift, and misleading aggregate scores.
Today, we’ll cover some of the considerations of choosing the right metrics (and in future installments we will dive into the other pillars as well!).
Choosing the right metrics
Different components of AI agents require different evaluation approaches. There is no universal metric.
Accuracy
Accuracy is the percentage of correct predictions in a binary right/wrong framework. It is often the default metric because it is simple and intuitive.
We often want to weigh certain categories differently. Weighting can be achieved in two ways:
- Explicit weighting counts certain examples (e.g., safety-critical cases) more heavily in the score.
- Implicit weighting includes more examples from important categories in the evaluation dataset.
Accuracy works well when:
- False positives and false negatives are roughly equally costly.
- Class distributions are reasonably balanced.
It becomes misleading when:
- One class dominates production traffic.
- A rare error is disproportionately costly.
- Different types of mistakes have asymmetric consequences.
Precision and recall
When mistakes have asymmetric costs, accuracy is insufficient.
- Precision answers: When we predict X, how often are we correct? Low precision = too many false positives.
- Recall answers: When X is truly present, how often do we catch it? Low recall = too many false negatives.
These metrics can be calculated overall or per category. In many production systems, per-category metrics are essential to uncover blind spots.
When optimizing:
- If false positives are costly (e.g., incorrectly escalating calls), prioritize precision.
- If false negatives are costly (e.g., missing a safety escalation), prioritize recall.
F1 score
The F1 score combines precision and recall into a single number. It is useful when you need a balanced tradeoff and cannot favor one error type strongly. However, F1 can hide asymmetry. It implicitly assumes that false positives and false negatives carry equal cost, which is rarely true in practice.
Two models can have identical F1 scores–while making very different tradeoffs–if one favors high recall with many false positives and the other favors high precision while missing critical cases. As such, it is often better to track precision and recall separately as well, and make an explicit decision about acceptable tradeoffs.
Specialized metrics
Various flavors of accuracy and precision/recall/F1 will suffice for a large number of use cases. But, certain components of AI agents demand domain-specific metrics for evaluation.
One common example is Automated Speech Recognition (ASR), which can be measured with Word Error Rate (WER), both overall and within specific information collection categories.
LLM-as-a-judge evaluations
Other subjective criteria for our AI agents, like naturalness, empathy, or goal-oriented behavior defy traditional automated evaluation. In these cases, LLM-as-a-judge scoring aligned with human raters is effective.
Rules of thumb for LLM-as-a-judge:
- Calibrate against human judgments. Tune the LLM judges until they line up with what knowledgeable human judges say.
- Use carefully. This technique introduces second-order model bias. Models grading models can be helpful, but intrinsically opens up a vulnerability to “gaming the system;” models often know how to tell other models what they want to hear without improving the real underlying behavior. To defend against this, see rule #1 🙂.
Remember that our primary goal is not to maximize a number… until we have defined a number worth maximizing.
The rest is often surprisingly feasible. And the results pay dividends when it comes time to measure the impact of AI agents on customer experience, business outcomes, system reliability, and more.
Schedule time with an expert to learn more about how expertly evaluated AI agents can transform your contact center.
