



.svg)



If you’re a close follower of the conversational AI space, you’ve seen the viral posts that regularly make the rounds: “World’s fastest voice bot!”, “Latency under 100ms!”, and the like.
Yet here in the real world, AI Agents never seem to match the speed of the demos that draw attention on social media. Why the gap?
Let’s dive into why that demo is so snappy and prepare you to ask the right questions of anyone making fantastical claims about their latency capabilities in a production setting.
Fast demos are engineered to be fast
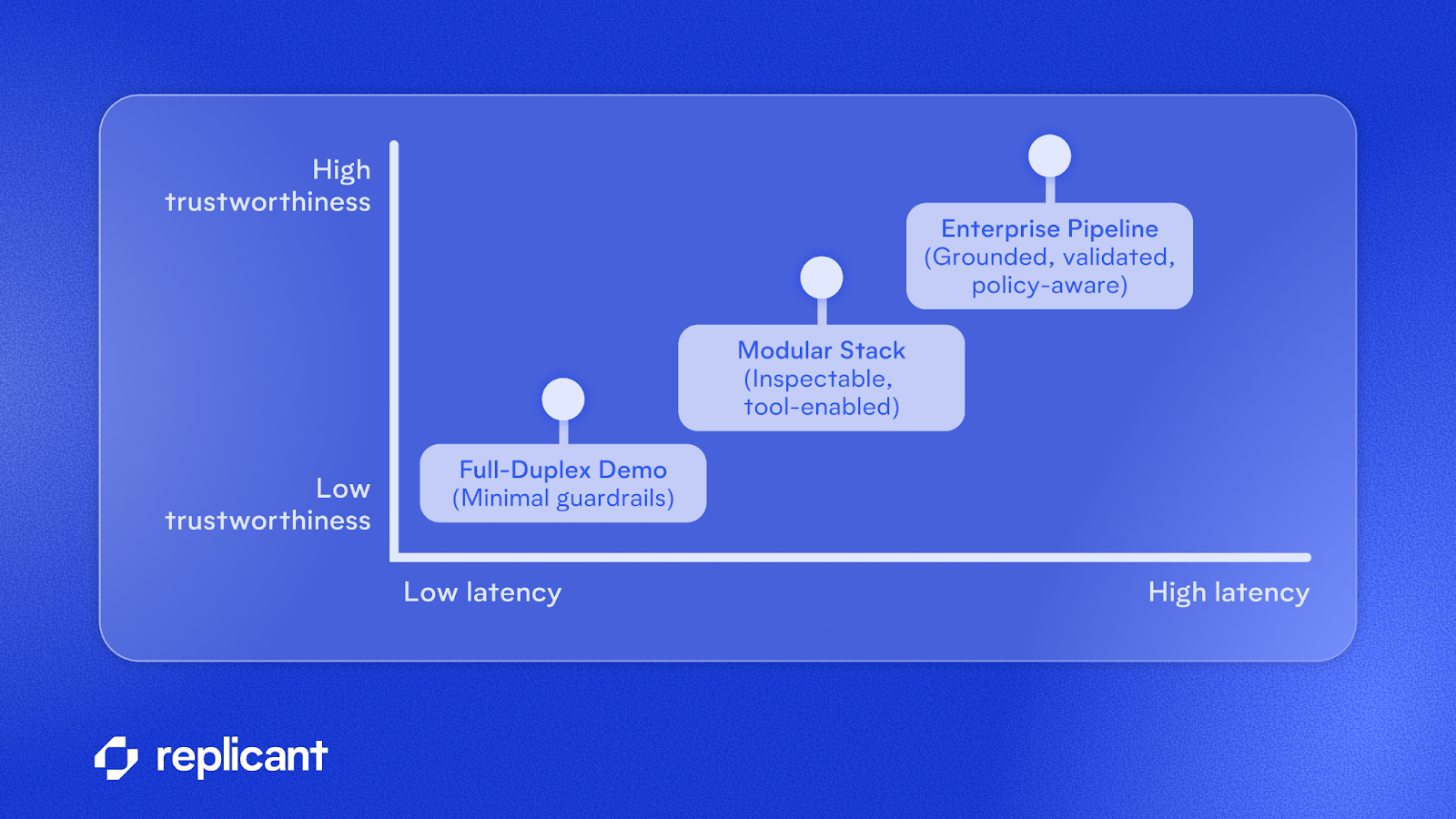
Let’s talk about an impressive demo: NVIDIA PersonaPlex. It’s a voice-to-voice model, meaning it skips the speech-to-text and text-to-speech steps employed by most conversational AI. The demo showcases natural conversational flows, interruptibility, and compelling personas.
PersonaPlex is “full duplex,” meaning it processes audio continuously. This architecture allows it to respond while it’s still receiving input, supporting overlapping speech and interruptions. The timing makes the bot feel more human-like than traditional voice AI.
What’s the catch? For the enterprise customer, these are deal-breakers:
- No support for tool calls or ability to invoke external APIs
- Lower predictability compared to traditional text-to-text models
- Nightmare QA: it’s impossible to know precisely what the model “heard” before it replied
- No support for guardrails necessary for compliance
The demo sounds impressive, but it’s a “you get what you get” scenario. Configure the persona of the bot and hope for the best! If you’re a contact center leader, you’re squirming in your seat already.
The modular architecture of enterprise conversational AI
At Replicant, we approach each conversational turn in three distinct steps: listening, reasoning, and speaking. In each step, we closely evaluate tradeoffs to maximize trustworthiness while minimizing latency.
In the listening step, we carefully tune our speech-to-text usage. Endpointing is the process of determining when a caller has finished speaking.
Context is important here: a person will answer a yes/no question quickly, but they might need more time, or have more pauses, when reading out their credit card number, for example. Endpoint too aggressively and you interrupt the caller; wait too long and there’s awkward silence.
In the reasoning step, we have to strike a similar balance between using the smartest, deepest-thinking models versus simpler models that provide answers more quickly. Thinking takes time! We also have to guard against hallucinations and mistakes.
Reasoning also involves calling customer APIs. After all, our AI Agents are not just bots chatting about the weather. Success is measured on their ability to do useful things for global, enterprise brands (like DoorDash). And doing useful things entails talking to external systems, which is not always instant.
In the speaking step, we balance quality with latency when choosing voice models. We consider factors like the inherent audio limitations of telephone calls, where telephony systems employ a codec from 1961 (!), and evaluate lower-latency text-to-speech models against their production voice quality on the phone.
The tradeoff: latency vs. trustworthiness
Demos skip safeguards, can’t call external systems, and don’t check for hallucinations. Modern, enterprise-grade conversational AI prioritizes trustworthiness over rock-bottom latency, striking a careful balance and employing thoughtful conversational design to deliver an efficient, trustworthy experience.
Latency as efficiency: not just about responding quickly
Have you ever gone to the doctor for a check-up and been asked a list of thirty consecutive questions, answering “no” to each and every one? The latency of feedback from the nurse is low, but the overall conversation is slow, plodding, and frustrating.
Wouldn’t it be nice if you could just say “none of that applies to me” at the beginning? And wouldn’t that option greatly reduce the duration of the overall interaction?
Latency is but one input to efficiency. Here’s where our conversational design expertise comes in. Replicant’s AI Agents have engaged in over 100 million conversations.
We designed those conversations. We iterated. We learned what works and what doesn’t, and our expertise directly affects the most impactful concept of latency: conversational efficiency.
Reducing perceived latency
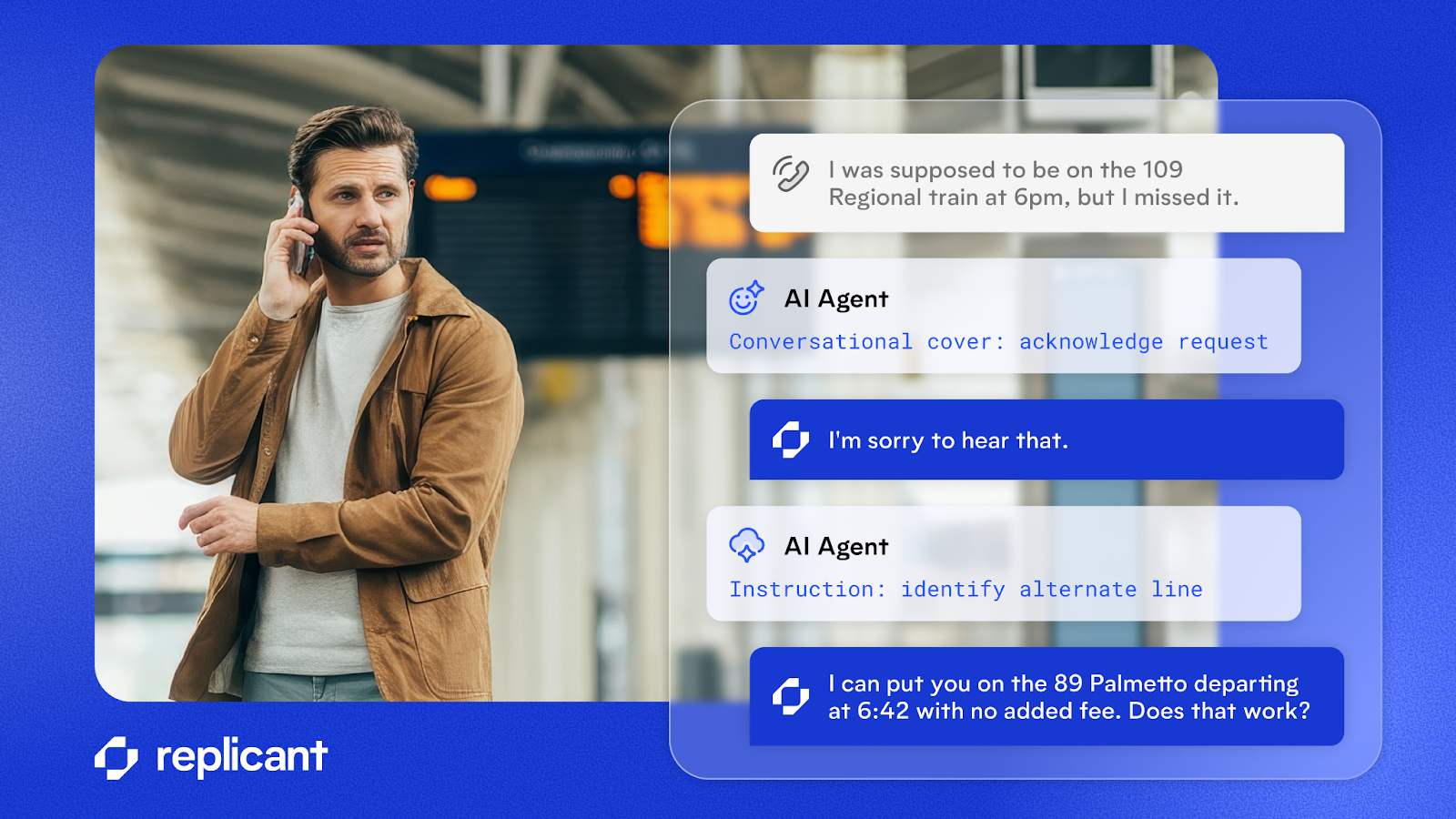
And we have a few tricks up our sleeve, of course. Conversational covers are a feature that reduces perceived latency rather than actual latency. Imagine you’re talking to a human agent, explaining your need to return a defective item you purchased last week.
While looking up your account, the agent might say, “I understand your frustration” or “Let me check that for you.” Conversational covers replicate this behavior in an AI Agent, delivering a quick, contextually appropriate signal to the caller that their voice has been heard but the AI Agent needs more time to fully process the call.
Final result: a natural conversation
Latency is a means to an end, and that end is a fluid, natural, efficient conversation. Minimizing latency is both an art and a science.
The art is in the conversational design. The science is in carefully assembling streaming architectures, the best models for the task, and tricks like conversational covers to reduce perceived latency.
And the result, while perhaps not optimal for viral demos, is an AI platform that resolves customer issues as fast as technology allows in complex, real-world scenarios.
Schedule time with an expert to learn more about how Replicant can transform your contact center with AI.
